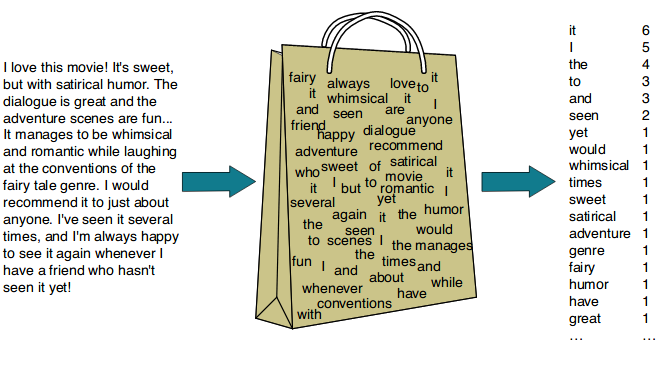
2) Bag of Words(BoW)(21.12.08)
Bag of Words란 단어들의 문맥이나 순서를 무시하고,
빈도 값(frequency)을 부여해 피쳐 값을 만드는 모델입니다.
Bag of Words는 직역하자면 단어들의 가방입니다.
문서 내 모든 단어를 한꺼번에 가방(Bag) 안에 넣은 뒤에 흔들어서 섞는다는 의미로 Bag of Words(BOW) 모델이라고 합니다.
( 글에서 키워드를 추출, 스팸 메일을 필터링, 긍정 vs 부정과 같은 감성 분석 )

원래 Bag of Words 기법은 문서(document)를 자동으로 분류하기 위한 방법중 하나로서, 글에 포함된 단어(word)들의 분포를 보고 이 문서가
어떤 종류의 문서인지를 판단하는 기법을 지칭한다.
영상처리, 컴퓨터 비전 쪽에서는 Bag of Words 기법을 주로 이미지를 분류(image categorization)하거나 검색(image retrieval)하기 위한 목적으로 사용하였는데, 최근에는 물체나 씬(scene)을 인식하기 용도로도 폭넓게 활용되고 있다.BoW의 피처 벡터화는 다음과 같이 두 가지 방식이 있습니다.
카운트 기반 벡터화(CountVectorizer), TF-IDF(Term Frequency - Inverse Document Frequency) 기반 벡터화
3) 문서 단어 행렬(Document-Term Matrix, DTM)
각 문서에 대한 BoW 기반 표현을 통해 문서의 정보를 벡터, 행렬화하는 것이 가능해진다.
문서 단어 행렬이라고 불리는 이 표현 방법은 위 BoW의 표현 방법대로 표현하되 복수의 문서를 하나의 행렬에서 표현한 것이다
단어/문서 단어 1 단어 2 단어 3 . . . 단어 m 문서 1 0 0 0 … 0 문서 2 0 0 0 … 0 문서 3 0 0 0 … 0 … … … … … … 문서 n 0 0 0 … 0
문서 단어 행렬(Document-Term Matrix)의 한계
희소 표현(Sparse representation)
대용량의 문서일 경우 엄청난
리소스가 낭비될 수 있다.
대부분 0을 차지하게 되고, 공간적, 시간적 리소스가 낭비될 수 있다.
때문에 칼럼을 하나라도 줄이기 위해 어간 추출, 불용어 처리 등을 통해 최대한 단어 집합의 크기를 줄이는 것이 성능 문제과 직결된다.단순 빈도 수 기반 접근
보편적으로 비슷한 문서에는 비슷한 단어가 등장할테지만,
예외적인 불용어들이 존재한다.
영어에는 “the”라는 단어가 빈도수가 높다고 해도 이 문서들을 유사한 문서라고 판단해선 안되기 때문이다.
각 문서에는 중요한 단어와 불필요한 단어가 혼용되고 있으며, 이를 적절히 선별해주는 전처리 작업이 필요하게 된다.
4) TF-IDF(Term Frequency-Inverse Document Frequency)
TF-IDF는 기존의 DTM에서
각 단어의 중요도라는 개념을 가중치로 부여하는 기법이다.
기존의 DTM을 사용하는 것보다 더 심도있게 접근할 수 있으며 보다 더 많은 정보를 고려하여 문서들을 비교할 수 있다.
이를 통해 주로 문서의 유사도, 검색 결과의 중요도 결정 등에 많이 사용된다.TF-IDF는
단어 빈도, 역문서 빈도의 줄임말로 이 2가지 값을 곱하는 것으로 계산할 수 있다.
각 개념의 의미와 공식은 다음과 같다.TF(d, t)
TF는
특정 문서 d에서 단어 t가 등장한 횟수를 말한다. 이는 기존의 DTM과 완전히 똑같은 개념이기 때문에 DTM 자체가 이미 TF 값인 셈이다.DF(t)
DF는
특정 단어 t가 등장한 문서의 수이다. 하나의 문서 내에서 얼마나 많이 등장했냐는 상관없다. 오직 등장했던 문서의 수를 뜻한다.IDF(d,t)
IDF는 기본적인 의미로는
DF의 역수, DF와 반비례하는 수를 뜻한다.
그러나 위 식은 단순히 df를 내리는 뿐만 아니라 log를 취하고 있는데, 이는 총 문서의 수 N이 커지면 커질 수록 값이 너무 커져버리기 때문에 log를 사용한다.
1을 더하는 이유는 단순히 분모가 0이 되는 것을 방지하기 위해서이다.각 DTM 값에 대응되는 단어의 IDF 값을 곱해주는 것으로 TF-IDF를 연산할 수 있다.
즉 TF-IDF란해당 문서에 해당 단어가 많이 등장하는 것이라면 중요한 것일 테지만, 애초에 모든 문서에서 많이 등장하는 단어였다면 그만큼 감점을 시키자라는 의도로 만들어진 수식이다.
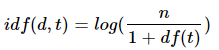
+ BoW의 한계
BoW의 한계와 n-gram
Bow는 단어 개수만 꺼내서 살피는 방식이기 때문에 단어의 순서를 무시한다. 그래서 등장하는 개념이 있으니 바로 n-gram이다. 예를 들어 “이 음식은 너무 맛있다”라는 문서가 있을 때 전통적인 Bow로 접근하면 각 단어(feature)는 “이”, “음식은”, “너무”, “맛있다” 가 될 것이다.
그러나ngram은 단어를 n개씩 묶어서 그걸 하나의 feature로 보는 개념이다.
그래서 만약 2개씩 묶은 bigram 모델을 사용하면 “이 음식은”, “음식은 너무”, “너무 맛있다” 가 된다. Bow는 각 단어를 독립적으로 고려하지만 이렇게 bigram, trigram과 같은 모델을 적용하면 단어가 나타나는 순서라든지 가까운 단어들을 함께 고려하게 되는 셈이라때에 따라 더 적절한 방법이 되기도 한다.BoW…
아무리 ngram 모델을 적용하더라도 Bow 모델은 그 빈도만 세기 때문에
맥락을 충분히 고려해야 하는 상황, 즉 텍스트를 생성한다거나 예측하는 등의 장면에는 활용이 어렵다.
게다가 학습된 단어 사전을 기반으로 하기 때문에사전에 없는 새로운 단어가 나타났을 때 그걸 처리할 방법이 없다.
학습 데이터에 지나치게 의존하기 때문에 오버피팅(overfitting)이 발생하는 것이다.
smoothing(평탄화)라는 방법을 통해 이 문제를 나름대로 어떻게든 해결하는 전략이 있긴 하다.
이미 알고 있는 단어들의 확률을 가지고 알려지지 않은 단어의 확률을 추정하는 방식이다.(?)